The Beacon Chain, and ETH2 Security/Upgrade paths
This is a followup to my post, Setting up a NUC for ETH Staking - Ubuntu, Nethermind, Lighthouse, Prometheus, Grafana.
This is essentially a mish mash of interesting knowledge that I have gained since setting up my rig. It includes:
- Information about the specification for the beacon chain
- Information about securing your setup
- Information about upgrading your setup
- Issues that I have encountered in practice
My view point is that if you understand exactly what you are working with, you are in a good position to resolve any issues when they happen (and they will).
Random Tidbits
- 32 slots per Epoch. Approximately 6.4 minutes.
- When sending your transaction to the deposit contract (on ETH1) it needs to contain the appropriate data such that the beacon chain can discern the sender. You can't just send 32 ETH.
- Effective balance differs to current balance.
- Current balance must increase by 1.25 to increase. E.g EB of 22 requires an CB of 23.25 to increase to 23.
- If all validators agree on last 2 epochs (justified) then all before that are finalized.
- Validator private key signs validator transactions
- Withdrawal private key allows withdrawal of balance from validator
- Ideally your attestation should get into the next block. An inclusion delay reduces your validator reward.
Slashable offences
- Double voting - don't have you validator keys associated with multiple validating machines at the same time.
- Surround votes
- Double proposals. Even if you were running two validators with the same key this is unlikely as block proposers are completely random.
Good Links
- Ben Edgington's annotated spec
- Vitalik's annotated spec
- Beacon Chain Overview
- Lighthouse Docs
- ETH2 Fork Monitor
- ETH2 Staking Best Practices
- ETH2 Slashing Protection Tips
- Python Bitwise Operators
Slashing Protection
Slashing protection databases are local to your validator client. They are essentially a log of things that have been signed locally that the validator can check before signing something else. If signing that 'something else' would lead to a slashable offence, the validator will not do so.
If changing validator clients/machines the slashing protection database should also be transferred.
Hard Drives
When buying hard drives I was very must aware of the TeraBytes Written (TBW) stat.
ETH1 Nodes write a lot of data. Geth is notorious for doing so.
Checking the health of your hard drives is important:
apt install smartmontools
#Short test - take ~2mins
smartctl -t short -a /dev/sda
#Long test - takes ~60mins
smartctl -t long -a /dev/sda
#View results
smartctl -a /dev/sdaMonitoring your setup
This reddit post outlines some decent ways of monitoring your setup:
I don't understand half of the Lighthouse Grafana dashboard, but here's what I've found useful:
Average Load – If there is a problem with finality or the beacon chain is still syncing, this can be high (and stay high)
Consensus > Validator Balances – Should be going up, means everyone is happy and earning ETH. When it's declining, it means we've probably got finality issues like we had on medalla
Consensus > Active Validators – Should be going up or flat, means we're not losing participants (like when test nets die)
Networking > libp2p Connected Peers – This should be hovering around 50 unless you specified a different target. I had a problem with an old data directory, and this was only showing 1 or 2 peers.
Logging > Crit Logs Total – Don't want to see anything here. I saw some critical errors at one point, related to the same data directory issue.
To ensure I'm validating correctly, I look at the validator logs, you want to see:
INFO All validators active (or Some validators active if some are pending)
INFO Successfully published attestation – Should see this every few minutes or so
INFO Successfully proposed block – Much rarer, but does happen occasionally
I also check beaconcha.in and have added my validators to my Dashboard and setup notifications for them. You should see:
State: Active
Last Attestation: A few minutes ago
If you drill-in to a validators Attestations tab, you should see a history of "Attested" and no "Missed" (or very few)
The main indicator of a problem is an email from beaconcha.in when a validator balance decreases for 3 consecutive epochs (by a tiny amount). Oh, and if my NUC's fans start kicking into high gear – that's a great sign something is wrong :)
Using free -m you can see actual system memory usage, noting that memory used for buffers/cache can be made available immediately and therefore is free.
total used free shared buff/cache available
Mem: 31985 5997 657 1 25331 25644
Swap: 8191 2 8189ps -aux to see what processes are running.
Interesting Videos
Video Notes
- Create duties one epoch ahead so you should have plenty of time (unless reorg).
- Make sure using optimised BLS library and taking advantage of all cores to produce attestations on time.
- Increase default peer limit to speed up propagation of attestations.
- Aggregates always created 2/3 way through slot (8 seconds)
- Aggregate propagation - only 1 block publisher. You have to find it. More chances of delays. If you don't find it in time you might be delayed a slot = 50% reward.
- If there is an empty slot you will get 50% reward even though there was nothing you could do.
Security
There is a great article here from CoinCashew.
SSH
I disabled password authentication, and setup key authentication.
ssh-keygen -t rsa -b 4096
One small note - I set up a key with a non default name (as I have numerous keys). SSH was still requesting a password as seemingly by default it only checks default key names I.E id_rsa.
ssh-add ~/.ssh/my_key_nameFirewall
By default Ubuntu has ufw disabled. I.E. There is no active firewall. Hence why during my setup when I wanted to access Prometheus for example I could simply type into my browser the server IP and port.
Fortunately my router also has its own firewall which means that when I tried to access Prometheus from outside my network the connection was refused.
That said, I want to enable ufw on the server such that if I change my router in the future I still have protection.
#As outlined in the linked article
#Lighthouse
sudo ufw allow 9000/tcp
sudo ufw allow 9000/udp
#Nethermind
sudo ufw allow 30303/tcp
sudo ufw allow 30303/udp
#Grafana
sudo ufw allow 3000/tcp
#Prometheus
sudo ufw allow 9090/tcp
#Enable
sudo ufw enable
sudo ufw status numbered
As a matter of interest, I wanted to make things insecure to then secure them such that I had a more complete understanding as to why I was secure.
It turns out that my router has port forwarding options that allow me to forward requests to my public IP address to the private IP address assigned to my server by the router.
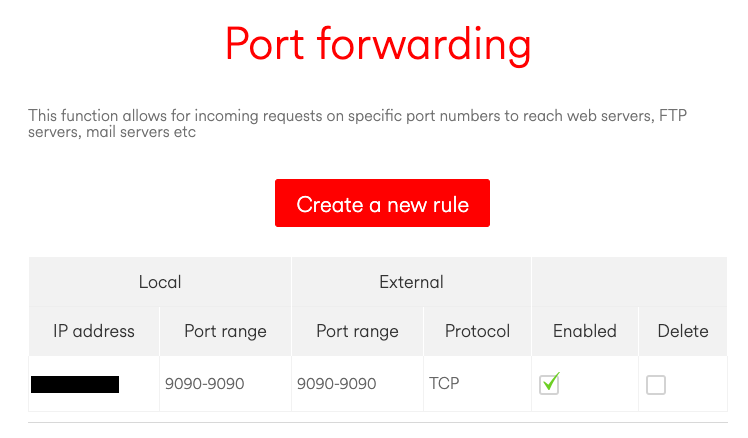
You can then use https://canyouseeme.org/ to test if that port is accessible to the whole world (and/or just type it into your browser). This allowed me to access my Prometheus dashboard from a completely different internet connection/network.
Port forwarding or port mapping allows remote computers to connect to a specific computer or service on a private network. This allows you to run a web server, game server or a service of your choosing from behind a router.
In a typical network the router has the public IP address and computers/servers obtain a private IP address from the router that is not addressable from outside the network. When you forward a specific port on your router, you are telling your router where to direct traffic for that port. This utility can verify the success of that process.
I end up with the following users:
grafana
lighthouse-beacon
lighthouse-validator
node-exporter
prometheus
nethermindIssues in Practice
These are some issues I have actually encountered playing on the test net and trying to break things.
WorkingDirectory
I set up a service to run Nethermind on the mainnet. I encountered an issue whereby Nethermind wasn't finding peers when running as a service.
It turned out that Nethermind was throwing exceptions but then zooming past them and continuing. This meant that I never saw the exceptions. Eventually I stumbled upon them.
Dec 11 11:21:14 nucolas Nethermind.Runner[315021]: 2020-12-11 11:21:13.9884|Step SetupKeyStore failed after 4484ms System.Security.Cryptography.CryptographicException: An error occurred while trying to encrypt the provided data. Refer to the inner exception for more information.
Dec 11 11:21:14 nucolas Nethermind.Runner[315021]: ---> System.UnauthorizedAccessException: Access to the path '/Nethermind' is denied.
Dec 11 11:21:14 nucolas Nethermind.Runner[315021]: ---> System.IO.IOException: Permission deniedThe issue was Nethermind being unable to access a certain folder because it was looking in the wrong place. The fix was to specify the WorkingDirectory in the service config.
Same Ports
At this point my Mainnet ETH1 sync was not working because it was trying to use the same discovery port 30303 as the testnet node. I wanted my mainnet node to use these defaults so I changed the testnet config to use port 30304. I also changed the JSON RPC port for the testnet to 8546.
My Nethermind goerli.cfg looked like this:
"Network": {
"DiscoveryPort": 30304,
"P2PPort": 30304,
"DiagTracerEnabled": false
},
"JsonRpc": {
"Enabled": true,
"Timeout": 20000,
"Host": "127.0.0.1",
"Port": 8546
},I didn't restart my beacon node at any point during this process out of intrigue as to what would happen when suddenly RPC calls on 8585 were returning data from the mainnet rather than the testnet. Fortunately Lighthouse has this covered:
Dec 11 11:55:27 nucolas lighthouse[150148]: Dec 11 11:55:27.350 WARN Invalid eth1 network id. Please switch to correct network id. Trying fallback ..., received: Mainnet, expected: Goerli, endpoint: http://127.0.0.1:8545, service: eth1_rpc
Dec 11 11:55:27 nucolas lighthouse[150148]: Dec 11 11:55:27.350 CRIT Couldn't connect to any eth1 node. Please ensure that you have an eth1 http server running locally on http://localhost:8545 or specify one or more (remote) endpoints using `--eth1-endpoints <COMMA-SEPARATED-SERVER-ADDRESSES>`. Also ensure that `eth` and `net` apis are enabled on the eth1 http server, warning: BLOCK PROPOSALS WILL FAIL WITHOUT VALID, SYNCED ETH1 CONNECTION, service: eth1_rpc
Dec 11 11:55:27 nucolas lighthouse[150148]: Dec 11 11:55:27.350 ERRO Failed to update eth1 cache error: Failed to update Eth1 service: "All fallback errored: http://127.0.0.1:8545 => EndpointError(WrongNetworkId)", retry_millis: 7000, service: eth1_rpcAs for the beacons nodes..
You can run both using the same ports if they are hidden within Docker containers, but given that I am not I needed to specify the appropriate config for the ports, data directories etc.
I wanted the mainnet to run with the default ports and Pyrmont to run on custom ports. I organised my data directories as required and then ran it using:
/usr/local/bin/lighthouse beacon_node --datadir /beacon-data/pyrmont --network pyrmont --staking --eth1-endpoint http://127.0.0.1:8546 --metrics --metrics-address 127.0.0.1 --port 9001 --http-port 5055 --metrics-port 5056And your validators..
/usr/local/bin/lighthouse validator_client --network pyrmont --datadir /mnt/ssd/lighthouse-validator-data/pyrmont --graffiti "ThOmAs" --beacon-node http://localhost:5055/The --beacon-node flag points to the http-port set on our beacon node, as outlined in a check of lighthouse vc --help:
--beacon-node <NETWORK_ADDRESS> Address to a beacon node HTTP API [default: http://localhost:5052/]Important Note: Going from a setup where I was running one testnet node/validator to one where I was running nodes on multiple networks required me to disable some of the services I had previously setup and create new ones with semantically clearer names like lighthouse-beacon-mainnet.
#Stop the old service
systemctl stop lighthouse-beacon
#Disable it - remove symlinks etc
systemctl disable lighthouse-beacon
#Move my previous service to a clearer named one
mv lighthouse-beacon.service lighthouse-beacon-testnet.service
#Copy the config
cp lighthouse-beacon-testnet.service lighthouse-beacon-mainnet.service
#Edit the respective files to contain the correct config
#Then reenable themWe also need to remember to enable the services so that they start on boot. e.g
systemctl enable lighthouse-beacon-mainnetYou can keep track of what is enabled with:
systemctl list-unit-files | grep enabledWrong Network
At this point I left it connecting to the wrong network to see what happens with missed attestations etc. I learned something.. I didn't miss any attestations (obvious in hindsight) - my validator was still running even if my beacon chain was not fully aware of the latest validators.
It took lots of further investigation to discern what the repercussions of the beacon node not being able to connect to ETH1 actually are.
The only details I can find on what an ETH1 node is actually used for come from Prysm:
Eth2 beacon nodes will track the eth1 chain's logs to determine deposits and verify those deposits' data to onboard new, proof of stake validators.
From Nimbus I found this:
Validators are responsible for including new deposits when they propose blocks. And an eth1 client is needed to ensure your validator performs this task correctly.
ETH1 Node Requirement
I was intrigued as to the ETH1 node requirement noting that having disconnected my ETH1 node I was still able to propose a block on the testnet.
My proposed block had outdated ETH1 data contained within which differed from the majority of other blocks proposed in that epoch.
I had expected to produce an invalid block and not get the reward.
dv8s on the Prysmatic Labs Discord channel provided some insight (even though I was using Lighthouse)
dv8S
it would be an issue if there were deposits that needed to be included (expected in the proposed blocks such as when a new eth1 block is voted in that has more deposits)
thomas123
If i look at my proposal the ETH1 data has a different block hash, deposit count, and deposit root to the other proposals in the epoch because it hasn't been connected to an ETH1 node for a few days. Could you clarify on what you mean exactly?
dv8S
once new eth1 data gets majority vote in a voting period, the deposit count increases and there is a need for the actual deposit data to be included in the proposed blocks.
this is not the eth1 data in a block
the eth1 data in a block is the actual vote
which can be just random, your block would still be valid
but most will have accurate eth1 data and once in the 64 epochs you get to >50% vote for a particular eth1 data
then further blocks needs to include the deposits
I read both Ben Edgington's annotated spec, as well as Vitalik's to get some further insight.
The former noted:
deposits: if the block does not contain either all the outstanding Deposits, or MAX_DEPOSITS of them in deposit order, then it is invalid.The annotations in the latter aided me with how block are processed by beacon chain clients.
def process_block(state: BeaconState, block: BeaconBlock) -> None:
process_block_header(state, block)
process_randao(state, block.body)
process_eth1_data(state, block.body)
process_operations(state, block.body)We process_eth1_data which makes a vote for the most up to date ETH1 state (subject to various rules - follow distance etc). The actual ETH1 data held in the beacon chain state is updated once a 50% majority vote for certain data. My invalid vote has no impact.
process_operations then handles things like including any deposit data which is required. My proposal was not invalid because whilst it included no deposits, there were no deposits that needed including.
If there had been deposits that needed including my proposed block would have been invalid. This is not a slashable offence, I'd simply miss out on the relatively larger block proposal rewards.
Screen
screen is the greatest thing ever. I wanted to setup a service such that if/when my server restarts, all of the logs that I like to regularly view and all of the tools with which I like to interact are opened automatically within a screen.
I set up a service as follows:
[Unit]
Description=Nucolas Background Tasks
[Service]
ExecStart=/usr/bin/screen -DmS screen-name -c /path/to/screen.screenrc
ExecStop=/usr/bin/screen -S screen-name -X quit
User=thomas
Group=thomas
StandardOutput=syslog
StandardError=syslog
Restart=always
[Install]
WantedBy=multi-user.targetand defined my .screenrc file as follows:
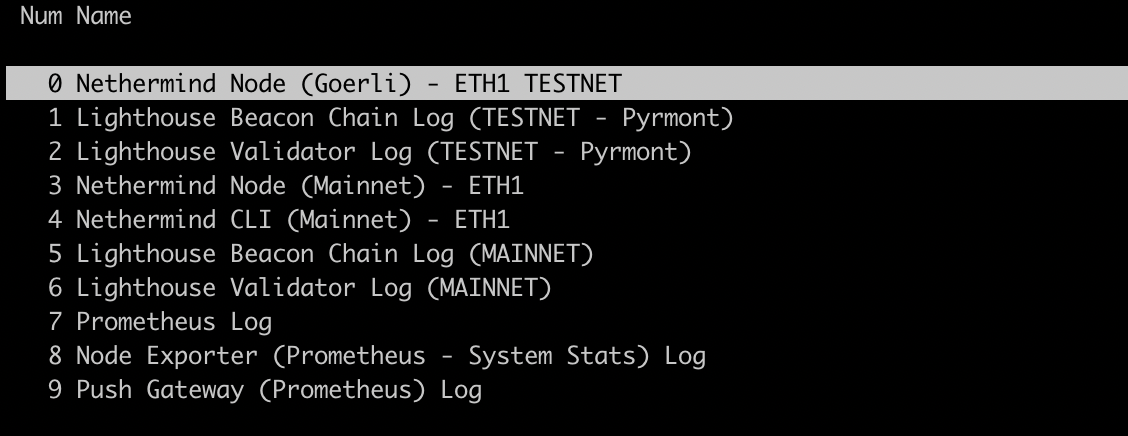
#Displays the log of the Goerli (Testnet) Nethermind Node
screen -t 'Nethermind Node (Goerli) - ETH1 TESTNET'
select 0
stuff "journalctl -fu nethermind-testnet^M"
#Beacon Chain Log - Lighthouse - Testnet (Pyrmont)
screen -t 'Lighthouse Beacon Chain Log (TESTNET - Pyrmont)'
select 1
stuff "journalctl -fu lighthouse-beacon-mainnet^M"
#Validator Log - Lighthouse - Testnet (Pyrmont)
screen -t 'Lighthouse Validator Log (TESTNET - Pyrmont)'
select 2
stuff "journalctl -fu lighthouse-validator-testnet^M"
#Displays the log of the Mainnet Nethermind Node
screen -t 'Nethermind Node (Mainnet) - ETH1'
select 3
stuff "journalctl -fu nethermind-mainnet^M"
#CLI Interface for Mainnet Nethermind
screen -t 'Nethermind CLI (Mainnet) - ETH1'
select 4
stuff "/home/nethermind/Nethermind.Cli^M"
#Beacon Chain Log - Lighthouse - MAINNET
screen -t 'Lighthouse Beacon Chain Log (MAINNET)'
select 5
stuff "journalctl -fu lighthouse-beacon-mainnet^M"
#Validator Log - Lighthouse - MAINNET
screen -t 'Lighthouse Validator Log (MAINNET)'
select 6
stuff "journalctl -fu lighthouse-validator-mainnet^M"The result is that if I start the service I can attach to it using screen -r screen-name and everything I want to see/use is already there.
If I detach from the screen Ctrl + a, d and then kill it screen -XS screen-name quit it will automatically restart itself :)
Push Gateway
In my previous setup I had left push gateway (for Prometheus) running in a docker container because it was a super simple one line setup. On playing with killing services etc (above) I noticed that push gateway hadn't been restarted so I installed it manually, setup a service for it and bought it inline with the rest of my setup.
wget https://github.com/prometheus/pushgateway/releases/download/v1.3.0/pushgateway-1.3.0.linux-amd64.tar.gz
useradd --no-create-home --shell /bin/false push-gateway
cp pushgateway-1.3.0.linux-amd64/pushgateway /usr/local/bin/pushgateway
chown -R push-gateway:push-gateway /usr/local/bin/pushgateway
vi /etc/systemd/system/push-gateway.service
systemctl daemon-reload
systemctl restart push-gatewayReboot
Lets see what happens when I reboot.
First time my Nethermind nodes wern't starting correctly.
They were not enabled:
systemctl list-unit-files | grep enabledI enabled them:
systemctl enable nethermind-testnetI tried again. Everything worked. That was easy.
Upgrading
Next I wanted to practice upgrading all the various pieces of software used in this setup. For reference (including links to their release pages), they are:
Since my initial setup Nethermind and Lighthouse have had updates. So this is not a drill.
Nethermind
#Stop the Nethermind services
systemctl stop nethermind-testnet
systemctl stop nethermind-mainnet
#Make a directory for the new version
mkdir nethermind-new
#Move to it
cd nethermind-new
#Download the latest release
wget https://github.com/NethermindEth/nethermind/releases/download/1.9.48/nethermind-linux-amd64-1.9.48-afb5880-20201214.zip
#Unzip/Untar as appropriate
unzip nethermind-linux-amd64-1.9.48-afb5880-20201214.zip
#Remove the archive
rm nethermind-linux-amd64-1.9.48-afb5880-20201214.zip
#Backup the previous version
mv /path/to/current/nethermind/ nethermind-old
#Move the new version
mv nethermind-new /path/to/current/nethermind
#Make sure it has the correct owner
chown -R nethermind:nethermind /path/to/current/nethermind
#Start the services
systemctl start nethermind-testnet
systemctl start nethermind-mainnetNote: This is why you practice upgrades 😂 - I forgot to copy over my config files so when I restarted my nodes they started resyncing from scratch (using the default data directories). Just as well I made that backup..
Lighthouse
In my initial setup I built Lighthouse myself. In this case I will use the prebuilt binaries.
#Stop the running services
systemctl stop lighthouse-beacon-testnet
systemctl stop lighthouse-beacon-mainnet
systemctl stop lighthouse-validator-testnet
systemctl stop lighthouse-validator-mainnet
#Make a directory for the new version
mkdir lighthouse-new
#Move to it
cd lighthouse-new
#Download the latest version
wget https://github.com/sigp/lighthouse/releases/download/v1.0.4/lighthouse-v1.0.4-x86_64-unknown-linux-gnu.tar.gz
#Untar it
tar -gvf lighthouse-v1.0.4-x86_64-unknown-linux-gnu.tar.gz
#Remove the archive
rm lighthouse-v1.0.4-x86_64-unknown-linux-gnu.tar.gz
#Move the lighthouse binary to where you want it
mv lighthouse /usr/local/bin/
#Check that it is the version you expect it to be
/usr/local/bin/lighthouse --version
#Stop the running services
systemctl start lighthouse-beacon-testnet
systemctl start lighthouse-beacon-mainnet
systemctl start lighthouse-validator-testnet
systemctl start lighthouse-validator-mainnetNote: At this point you will want to check your logs and make sure nothing untoward is displayed. Make sure your validators are validating etc. Check beaconcha.in etc
Alerts
I am told that beaconcha.in offers a great alerts system to get email notifications when interesting things happen.
Whilst playing with Grafana I saw that it offered some cool alert features, so i set some up.
I am using dashboards designed by others. I am pretty inexperienced with Grafana but it was fairly easy to view the PromQL used to generate the various graphs to setup alerts for some interesting scenarios.
For example, I set up an alert for if my nodes get more than 50 JSON-RPC requests per minute. The Beacon chain queries my ETH1 nodes seemingly around 30 times per minute. If it goes above this, something weird is probably happening.
First you need to make a query the result of which you want to base your alert off of. Note that you can not use queries that contain template variables.
I also disabled the query from showing in the visual representation by clicking the eye icon in the top right.

Then you click the 'Alerts' tab and set up an alert.
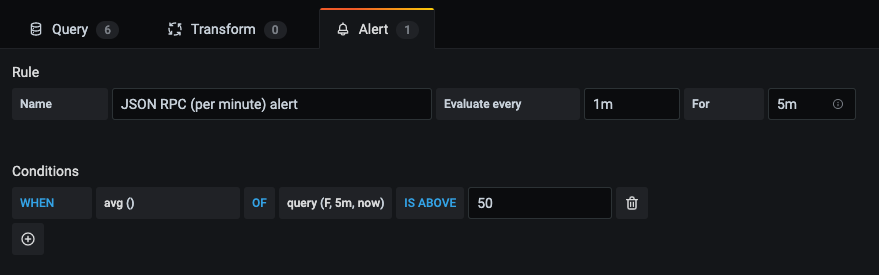
Set up as many alerts as you want for whatever arbitrary data queries you desire.
Powercuts
Never had a power cut before in my house. Just had one 😂 The universe is helping me test.
When power was restored the machine didn't automatically power back on.
It was just a case of pressing the power button and then because of all the above I was validating again within 30 seconds.
Thats all..
Thats all for now. I will almost certainly update this with more stuff, but in the interest of getting this out in the world..